简单工厂、工厂方法与抽象工厂之间的联系与区别
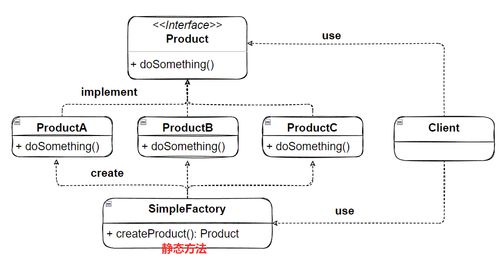
在软件开发中,工厂模式是创建型设计模式的重要组成部分,主要包括简单工厂、工厂方法和抽象工厂。它们在数据处理场景中广泛应用,用于封装对象的创建过程,提高代码的灵活性和可维护性。以下将详细讨论它们之间的联系与区别。
一、联系
- 共同目标:这三种工厂模式都旨在解耦对象的创建与使用,客户端无需关心具体对象的创建细节,只需通过工厂获取实例。这使得代码更易于扩展和维护。
- 数据处理的适用性:在数据处理中,例如处理不同类型的文件(如CSV、JSON或XML),这些模式可以帮助动态选择数据解析器或处理器,简化数据流管理。
- 面向接口编程:它们都鼓励使用接口或抽象类来定义产品,确保客户端代码依赖于抽象而非具体实现,从而提高系统的可测试性和可扩展性。
二、区别
- 简单工厂模式:
- 结构:只有一个工厂类,根据传入的参数决定创建哪种产品实例。
- 数据处理示例:在数据导入系统中,一个简单工厂可能根据文件扩展名(如.csv或.json)返回相应的解析器对象。
- 优点:实现简单,适用于产品类型较少的情况。
- 缺点:不符合开闭原则,添加新产品需要修改工厂类。
- 工厂方法模式:
- 结构:定义一个创建对象的接口,但让子类决定实例化哪个类。每个产品对应一个具体工厂。
- 数据处理示例:在数据转换系统中,可以有CSV转换工厂和JSON转换工厂,分别创建对应的转换器对象。
- 优点:符合开闭原则,易于扩展新产品。
- 缺点:可能会导致工厂类数量增加,增加系统复杂度。
- 抽象工厂模式:
- 结构:提供一个接口用于创建相关或依赖对象的家族,而不需要指定具体类。
- 数据处理示例:在数据导出系统中,一个抽象工厂可能定义创建数据导出器和格式化器的方法,例如数据库导出工厂创建数据库导出器和SQL格式化器,而文件导出工厂创建文件导出器和CSV格式化器。
- 优点:支持产品家族的创建,确保产品之间的兼容性。
- 缺点:结构复杂,添加新产品族需要修改抽象工厂接口。
三、在数据处理中的实际应用
在数据处理流程中,这些模式可以协同工作。例如,简单工厂用于快速选择数据源类型,工厂方法用于处理特定数据格式的转换,而抽象工厂用于管理整个数据导出流水线。通过结合使用,可以实现高效、可扩展的数据处理系统。
简单工厂、工厂方法和抽象工厂在数据处理中提供了不同层次的抽象。简单工厂适合简单场景,工厂方法强调扩展性,而抽象工厂适用于复杂的产品家族。开发者应根据具体需求选择合适模式,以优化数据处理架构。
如若转载,请注明出处:http://www.smxlzj.com/product/3.html
更新时间:2026-02-28 06:23:30









